Stata o SPSS... ¿Cuál es mejor? (Primera parte)
Entre los paquetes estadísticos más usados están (nombrados sin tomar en cuenta la frecuencia de su uso):
- SAS
- Stata
- SPSS
- R
- Epi Info
Cada software tiene sus fortalezas y sus debilidades, en este post me voy a centrar en comparar Stata y SPSS. La respuesta a cuál de estos dos softwares es mejor no es fácil, sin embargo tengo algunas observaciones como usuario que podrían contribuir a responderla, sin embargo dos factores son importantes: la experiencia del usuario analizando datos y el tiempo disponible para familiarizarse con el software. La segunda parte de esta comparación se encuentra abajo y compara Stata y SPSS en función del manejo de missing values.
Para comparar en términos de la experiencia del usuario ilustrar la comparación en este post voy a realizar una tabla de contingencia (o tabla 2x2) en SPSS y luego una tabla similar en Stata. Luego voy a comentar acerca del tiempo disponible para familiarizarse con el software y finalizo este post con la conclusión.
- Experiencia del usuario analizando datos: Si estás en las primeras etapas en el mundo del análisis de datos SPSS es el software de elección. La razón es porque tiene una interfaz amigable basada en el uso del menú. Voy a iniciar la compración realizando la tabla de contingencia en SPSS y más abajo mostraré lo que se requiere para hace esta tabla usando comandos en Stata. Veamos en las siguientes figuras el proceso para realizar análisis bivariado con una tabla de doble entrada o también llamada tabla de contingencia (el análisis bivariado involucra dos variables, generalmente aunque no siempre la variable dependiente y la independiente) Para mostrar este proceso en SPSS voy a utilizar la base de datos de ejemplo llamada accidents que está en la carpeta IBM en el disco duro.
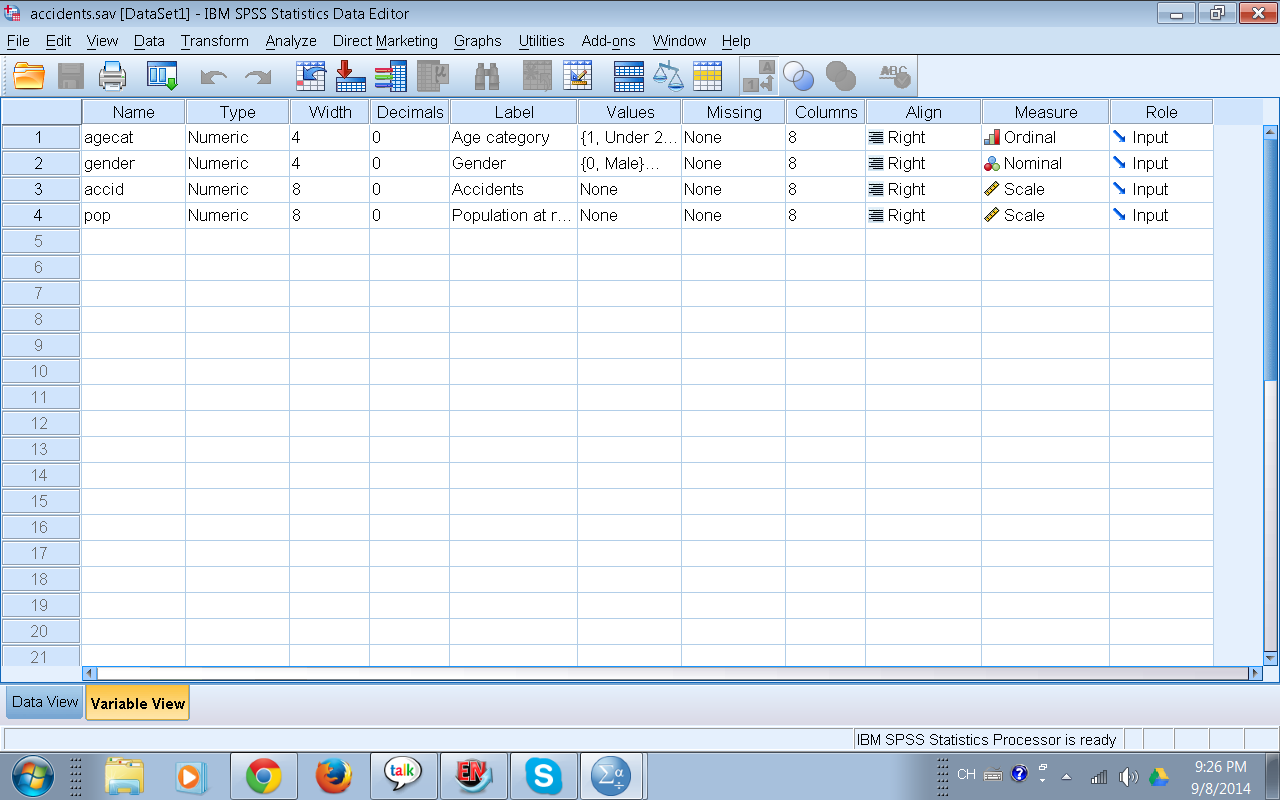
Voy a construir una tabla de doble entrada (también llamada crosstabs) usando las variables gender (género) y agecat (categoría de edades)
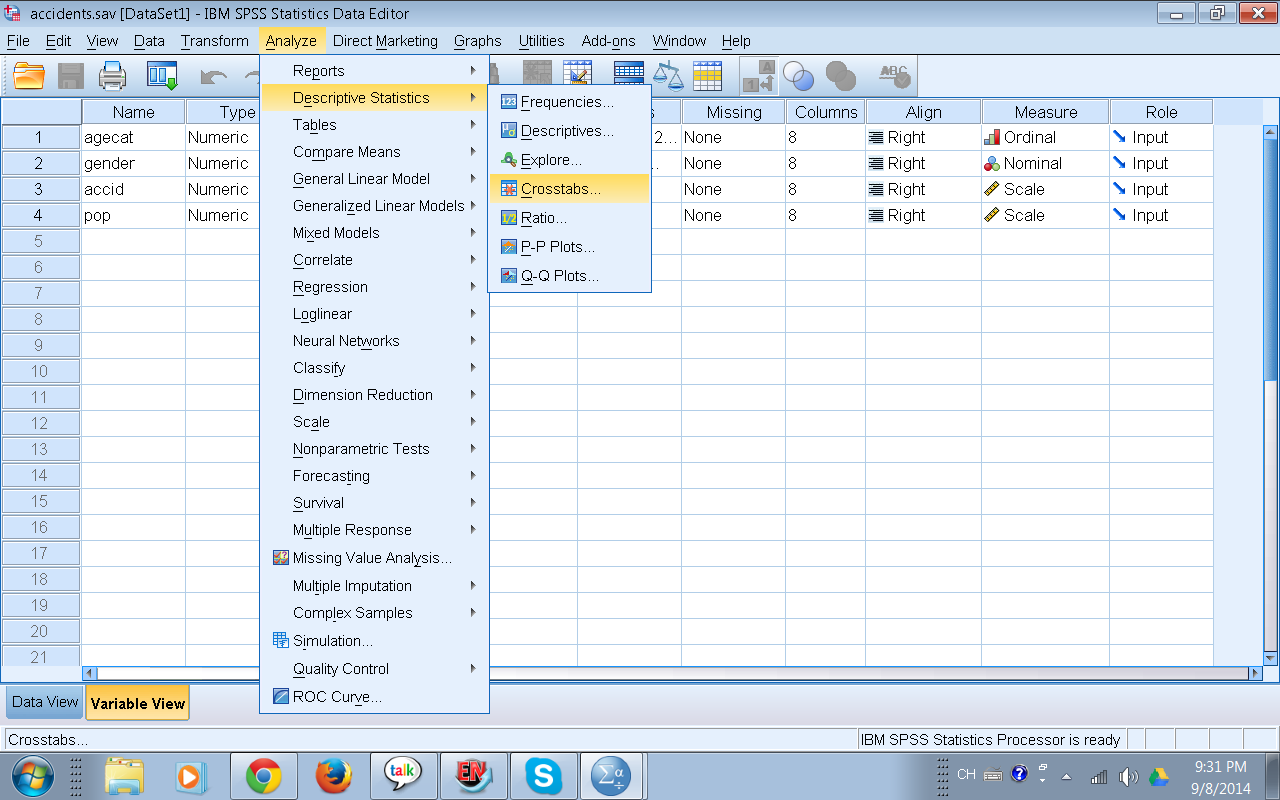
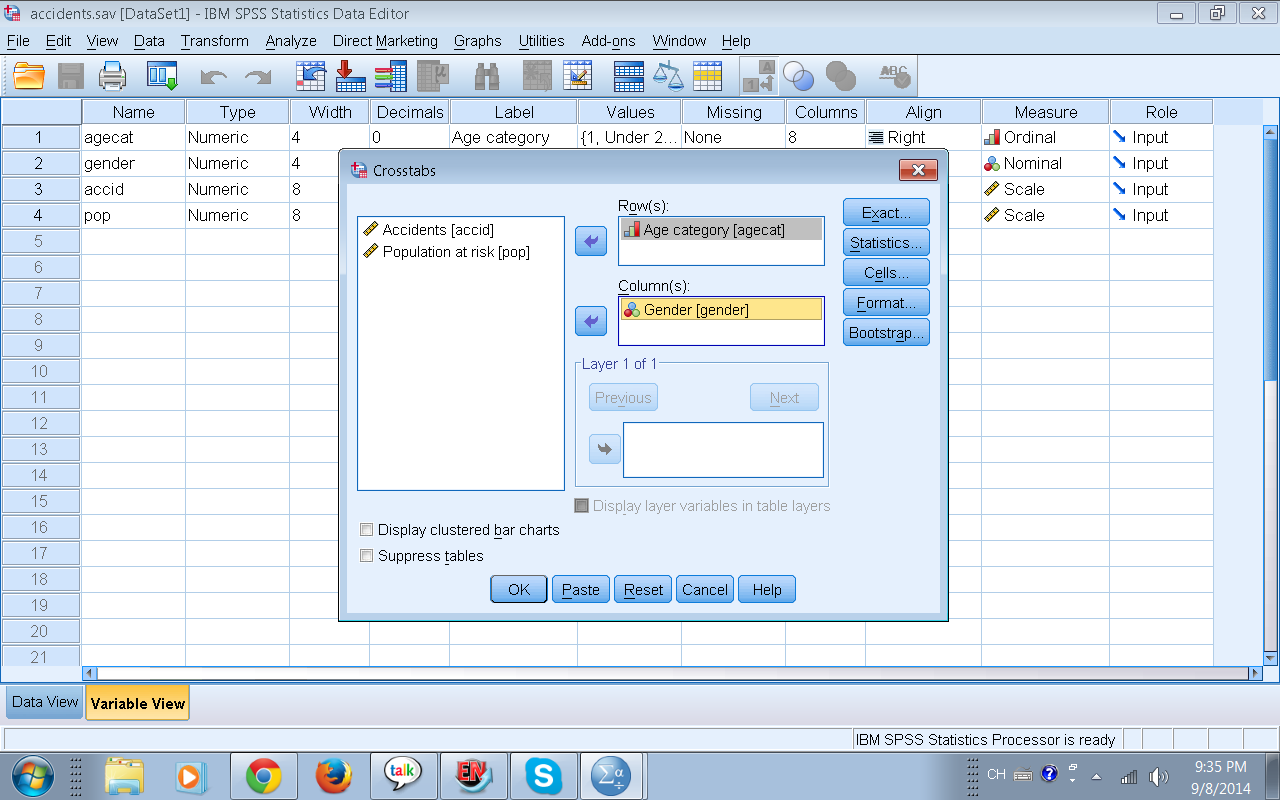
Una vez que damos click en Crosstabs entramos a la imagen de abajo y aqui viene la pregunta ¿qué variable va en las columnas y cuál en las filas? Si estuvieramos hablando en el contexto de variable dependiente e independiente diría que en general la variable dependiente va en las columnas y la independiente en las filas, sin embargo para este ejemplo es recomendable colocar la variable con menos categorías (o niveles) en las columnas, así la tabla va a lucir menos ancha y será más fácil de leer.
Antes de dar click en OK (abajo a la izquierda) debemos seleccionar la opción de porcentajes en la tabla, ¿cómo aparecerán los porcentajes en columnas? o en filas? Si no seleccionamos esta opción y damos opción obtendremos una tabla sin porcentajes. Demos click en Cells para entrar a la opción donde podemos seleccionar los porcentajes, veamos:
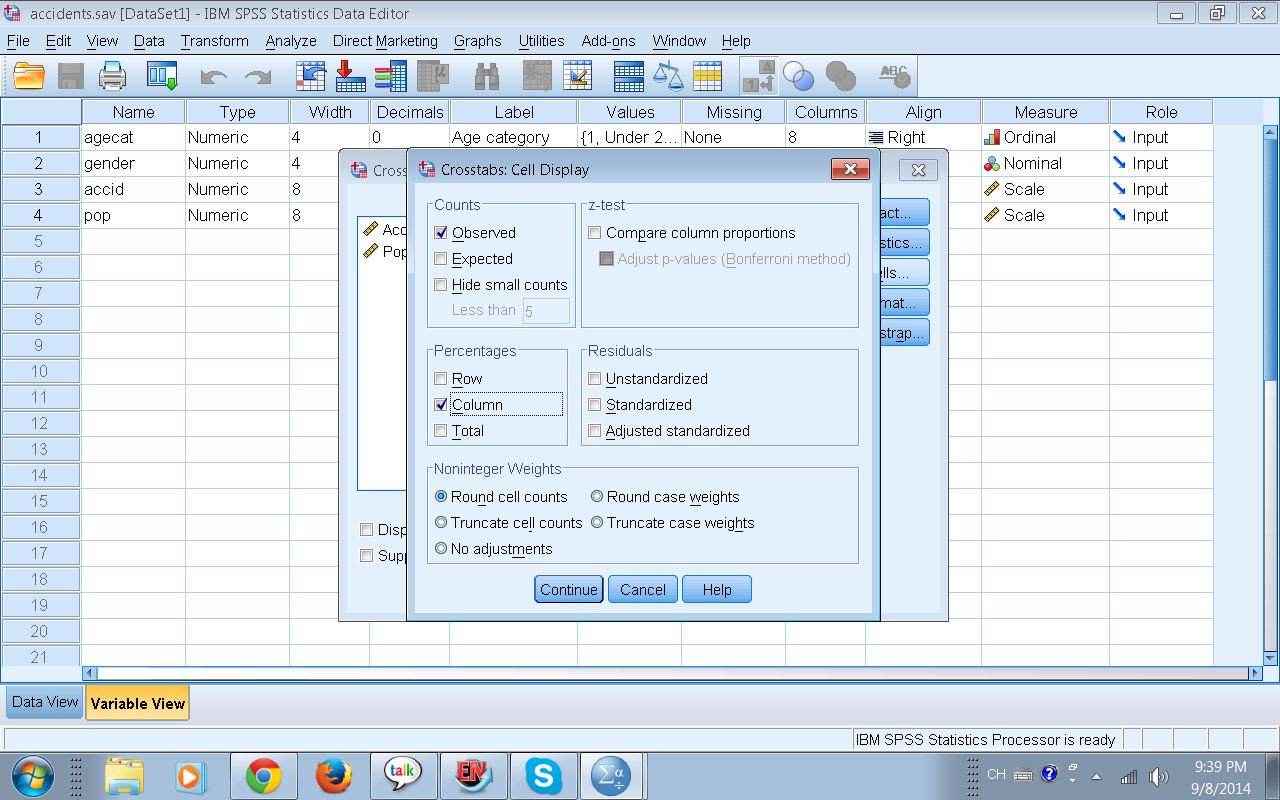
La respuesta si seleccionar filas o columnas se basa en el tipo de Diseño de Investigación del que los datos son extraídos. En estudios de Corte Transversal y de Casos y Controles se debe seleccionar columnas; en estudios longitudinales (por ejemplo cohorte) se debe seleccionar filas. En este ejemplo voy a asumir que el estudio es Corte transversal, por tanto he seleccionado columnas, luego doy click en Continue para volver a la pantalla anterior y luego click en OK para ejecutar la orden y ver mi tabla.

Para continuar con la comparación veamos cómo se realizaría una tabla de doble entrada en Stata, para ilustrar este proceso voy a utilizar una de las bases de datos de ejemplo de Stata, veamos como acceder a estas bases:
Le doy click en Example datasets y entro a la siguiente pantalla:

Le doy click en Stata 12 manual datasets y accedo a la siguiente pantalla:
Debido a que para propósitos de este análisis requiero una base de datos sencilla doy click en Base Reference Manual [R] y entraré a la siguiente pantalla donde doy click en use (al lado derecho de automiss.dta
Luego de dar click regreso a la ventana de datos de Stata:

Ahora una vez que he abierto mi base de datos voy a hacer la crosstab con las variables llamadas foreign (si el vehiculo es de fabricación extranjera o no) y weght (el peso del vehiculo categorizado como bajo y alto), para este fin tecleo el comando tab foreign weght, co y obtengo el siguiente resultado:
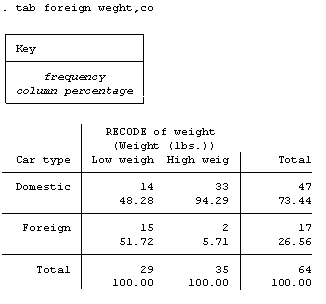
Lo que tomó tres paso en SPSS (ir a crosstab, poner las variables en filas y columnas y seleccionar el tipo de porcentaje) se hace con un comando de cuatro palabras y una coma.
2. Tiempo para familiarizarse con el software: SPSS requiere menos tiempo para familiarizarse porque ahi está el menú para recordar donde dar click, en cambio en Stata en las primeras etapas se debe memorizar los comandos más comunes lo cual requiere tiempo.
En conclusión la respuesta a cuál es mejor depende inicialmente del nivel de experiencia del usuario y del tiempo disponible para entrenarse en el uso del software. Aunque inicialmente usé SPSS hoy por hoy me inclino por Stata debido a que tiene herramientas para lidiar con los missing values (con lo cual uno termina ahorrando mucho tiempo durante el análisis de datos) , ocupa menos espacio en el disco duro (consume menos memoria de la computadora, sus bases de datos de ejemplo están en internet no en el disco duro y sus resultados pueden ser guardados en formato txt) y finalmente debido que tenés que escribir los comandos te da la sensación de mayor control sobre lo que estás haciendo, digamos la sensación de escribir qué variables estás incluyendo en tu modelo refuerza la sensación de control.
Stata o SPSS: ¿Cuál es mejor?: Comparación en función del manejo de missing values (Segunda parte)
En
el post anterior comparé Stata y SPSS en función de la familiaridad del
usuario con el análisis de datos y en función del tiempo disponible
para aprender uno u otro software. Debido a que el menú de SPSS es más
intuitivo que el de Stata, SPSS es recomendado cuando estás iniciando en
el mundo del análisis de datos. Sin embargo, si estás familiarizado con
programación (escribir códigos o comandos) y tienes más experiencia en
análisis de datos Stata ofrece opciones adicionales a SPSS que te ayudan
a ahorrar tiempo y a tener una mejor perspectiva de tus datos. Aqui
comparto una de mis opciones favoritas de Stata, la cual no está
disponible en SPSS.
La
intención de este post es más que mostrar uno de los comandos para
identificar la distribución de missing values (lo cual puede ser
encontrado en el manual de Stata) es destacar su utilidad con un ejemplo
real en el contexto de Metodología de Investigación.
1.- El manejo de los missing values. Un
paso importante antes de empezar a iniciar nuestros datos es ver si
nuestros datos tienen o no missing values y si tienen cómo están
distribuidos en las variables.
Supongamos que estamos interesados en analizar la relación entre Area de residencia (Urbano o Rural; variable independiente) y Estado civil (Casada, soltera y viuda; variable dependiente) en este análisis utilizaremos una tercera variable (edad, la cual será considerada variable confusora/confounding).
Antes
de pasar al patrón de missing values veamos cuántas observaciones tiene
nuestro dataset/base de datos y cuántas variables, para esto usamos
cualquiera de los dos siguientes códigos/comandos:
des, short
describe
Este
es el resultado al usar des, short. Tenemos 35 673 personas, 3
variables y luego información acerca del tamaño del dataset.

Este es el resultado usando describe:

Ahora la pregunta es: ¿Cómo puedo ver el número de missing values en mi dataset/base de datos? en otras palabras ¿Está completa la información de las tres variables o hay missing values? Voy a usar el comando mdesc para averiguar esto, veamos el resultado:
Este es el resultado :

¿Qué significa este resultado?
Significa que las variables Residence Area y Age tienen 3 858 missing
values, es decir 3 858 personas de este dataset no tienen información en
las variables Residence Area y Age.
¿Qué implicaciones tienen los missing values para nuestro análisis? Una
gran cantidad de missing values puede afectar la validez (the validity)
de nuestro estudio, en otras palabras puede llevarnos a conclusiones
erróneas. En este momento cabe preguntarse: ¿son esas 3 858 personas con
missing values diferentes a los que no tienen missing values? ¿Esas 3
858 personas eran del área rural o eran mayoritariamente del área
urbana? ¿Eran más jovenes que los que tienen información completa o eran
mayores? Cuando las obsevaciones que tienen missing values son
diferentes a los que no la validez de nuestros resultados podría verse
comprometida debido a sesgo de selección.
Conclusión:
- No basta saber únicamente el número de observaciones en nuestro dataset, sino si hay también missing values y cuáles son las variables con missing values.
- mdesc es una entre varias alternativas que Stata ofrece para describir la distribución de missing values.
- Debe encontrarse la manera de identificar si las observaciones con missing values son diferentes a la muestra de estudio.
- SPSS no ofrece una opción directa que al igual que mdesc nos de la distribución de missing values.
¿Cómo lucen nuestros datos después de digitarlos?
Una vez que terminamos la digitación de datos y exportamos la base de datos (desde Access, Epi Info o Excel) a Stata nuestros datos lucirán así:

¿Por dónde empezar? Nuestro análisis no puede estar desvinculado de nuestra hipótesis u objetivos de investigación los cuales deben estar escritos en nuestra propuesta (protocolo) de investigación . Los siguientes pasos constituyen una guía para iniciar el análisis cuantitativo de nuestros datos.
1.-¿Cuál es nuestra variable dependiente (también llamada variable resultado o Y)? Es conveniente identificar en nuestra base de datos cuál es el nombre de nuestra variable dependiente. ¿Existe en la base de datos? o debemos construirla? En caso de que ya exista debemos modificar el número categorías? Supongamos que nuestra variable dependiente es Nivel educativo de mujeres en Edad Fértil y que nosotros estamos interesados en Educación Primaria y Educación Secundaria. ¿Dónde está esta variable en nuestra base de datos? En la penúltima columna de la base de datos está la variable edu (Nivel Educativo de las Mujeres en Edad Fértil) ¿Qué tipo de variable es edu? Basados en la inspección del Editor de datos (primera figura) sospechamos que esta variable es continua, comprobemos nuestra presunción calculando el promedio (aunque basta con calcular el promedio para saber si es númerica o no también Stata nos da la desviación estándard , el mínimo y el máximo)
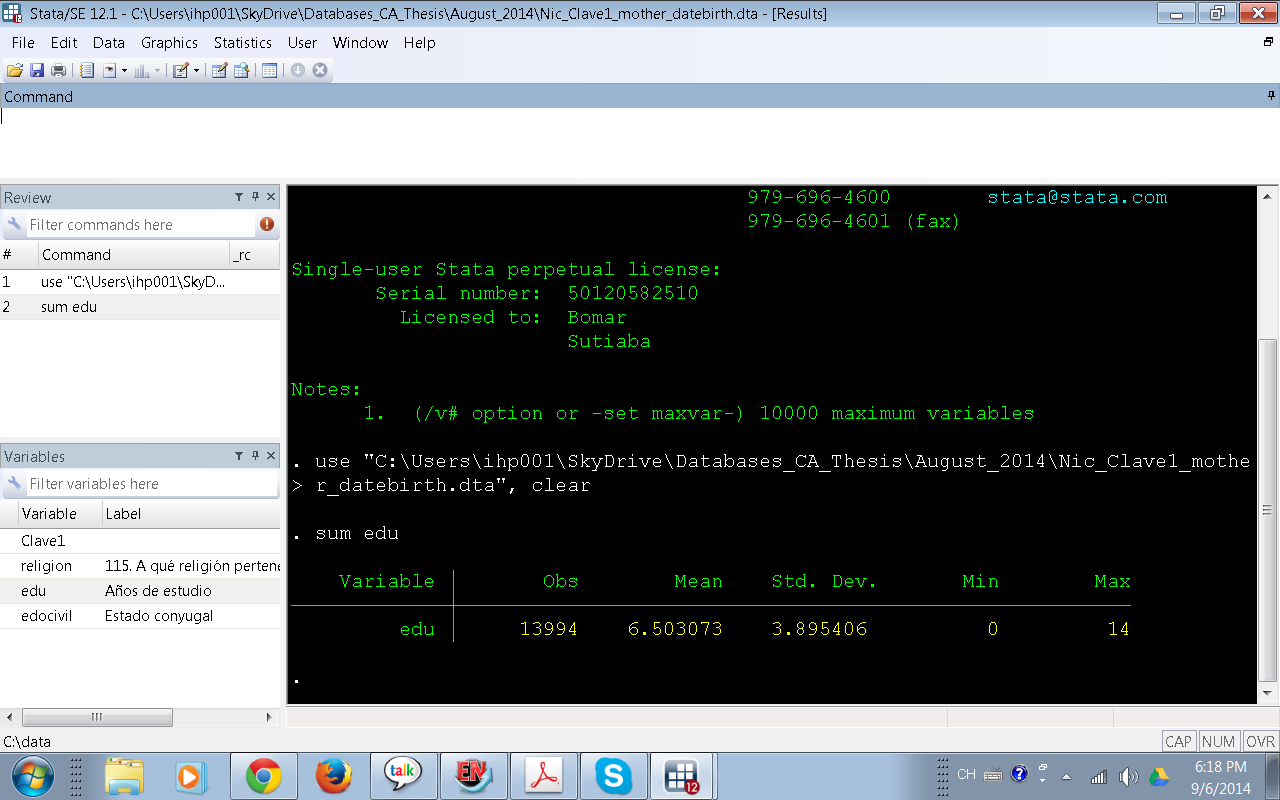
Vemos que es una variable continua (numérica) que contiene información del total de años de estudio por cada Mujer en Edad Fértil. El mínimo es cero años y el máximo 21 años, el promedio de años de estudio es 7.2 años y la desviación estándard es 4.56 ¿Qué debemos hacer a continuación? Debido a que nuestro interés es tener una variable dependiente dicotómica (de dos categorías: Educación Primaria y Educación Secundaria) claramente debemos recodificar la variable continua para transformala a categórica. Está más allá de los objetivos de este post mostrar como se recodifica una variable.
2.-¿Cuál(es) es(son) nuestra(s) variables independientes (también llamada variable predictora/explicativa o X)? Igualmente a como identificamos la variable dependiente debemos identificar la o las variables independientes . Supongamos que en nuestra investigación las variables independientes son: religion y Edocivil (Estado civil). ¿Existen en la base de datos?Claramente en el editor de datos vemos (primera imagen) que existen. ¿Qué tipo de variable es y cuántas categorías tiene? Para responder estas preguntas debemos hacer una frecuencia de cada una de estas variables, veamos para Religión:
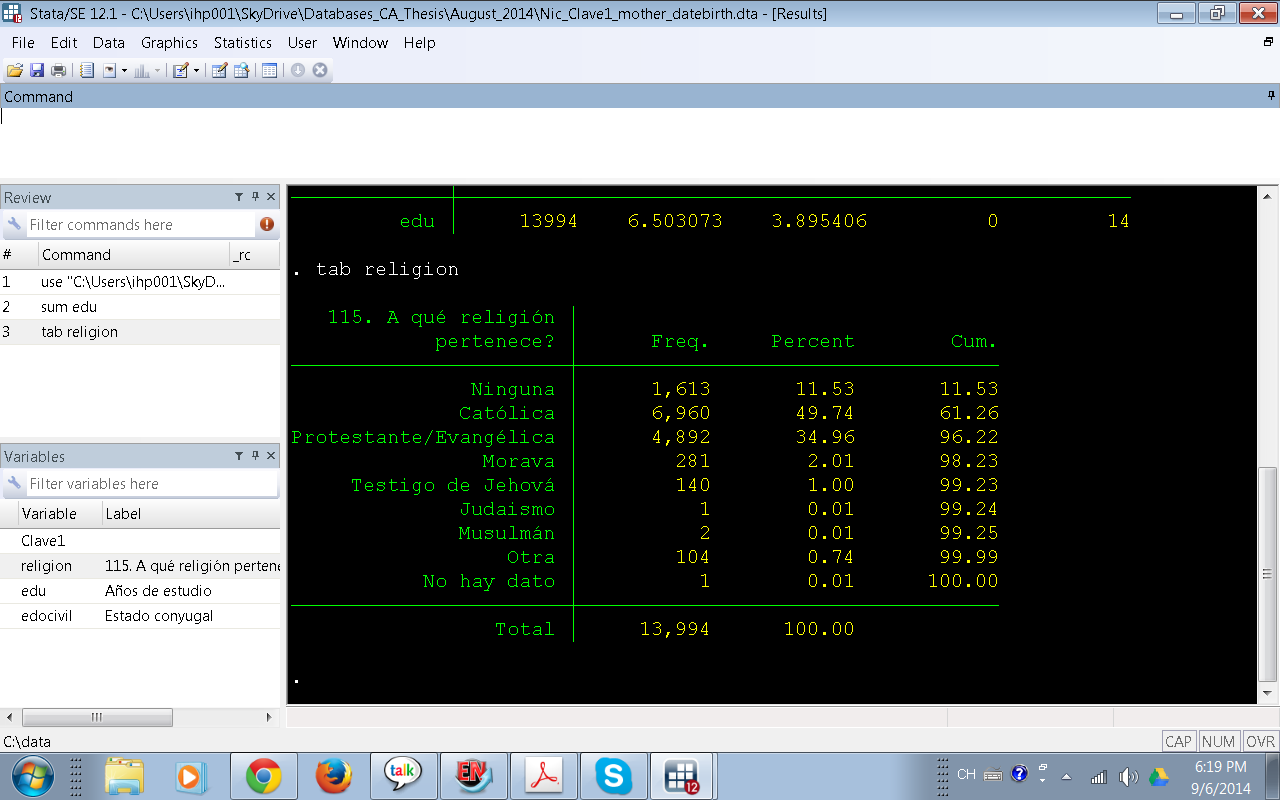
Ahora veamos la frecuencia simple para Estado Civil

¿Entonces qué tipo de variables son religion y edocivil? Son variables categóricas. Dependiendo de nuestro interés es posible que necesitemos o no recodificar estas variables debido a que algunas categorías tienen relativamente pocos casos en comparación con otras, por ejemplo hay 61 observaciones en la categoría "Divorciada", esta categoría se podría fusionar con "Separada", "Viuda" y "Soltera" para crear una nueva categoría llamada "Sin Pareja", pero va más allá de los objetivos de este post mostrar cómo se recodifica una variable.
En conclusión:
- Identifiquemos las variables dependiente e independientes.
- Realicemos frecuencia simple (para variables categóricas) o promedio (para variables numéricas) para evaluar si es necesario modificar las variables (por ejemplo transformar una variable continua a categórica o recodificar las variables).
No hay comentarios:
Publicar un comentario