En el post anterior comparé Stata y SPSS en función de la familiaridad del usuario con el análisis de datos y en función del tiempo disponible para aprender uno u otro software. Debido a que el menú de SPSS es más intuitivo que el de Stata, SPSS es recomendado cuando estás iniciando en el mundo del análisis de datos. Sin embargo, si estás familiarizado con programación (escribir códigos o comandos) y tienes más experiencia en análisis de datos Stata ofrece opciones adicionales a SPSS que te ayudan a ahorrar tiempo y a tener una mejor perspectiva de tus datos. Aqui comparto una de mis opciones favoritas de Stata, la cual no está disponible en SPSS.
La intención de este post es más que mostrar uno de los comandos para identificar la distribución de missing values (lo cual puede ser encontrado en el manual de Stata) es destacar su utilidad con un ejemplo real en el contexto de Metodología de Investigación.
1.- El manejo de los missing values. Un paso importante antes de empezar a iniciar nuestros datos es ver si nuestros datos tienen o no missing values y si tienen cómo están distribuidos en las variables.
Supongamos que estamos interesados en analizar la relación entre Area de residencia (Urbano o Rural; variable independiente) y Estado civil (Casada, soltera y viuda; variable dependiente) en este análisis utilizaremos una tercera variable (edad, la cual será considerada variable confusora/confounding).
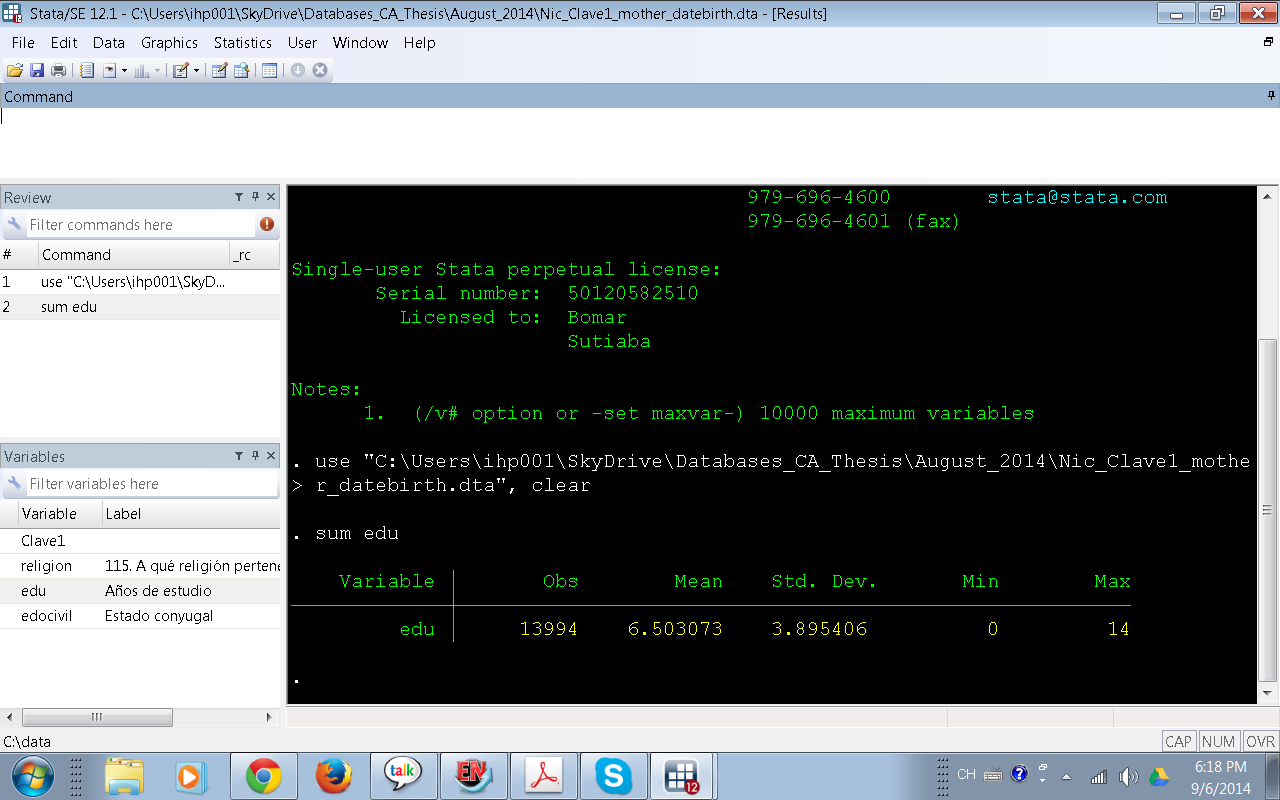
Antes de pasar al patrón de missing values veamos cuántas observaciones tiene nuestro dataset/base de datos y cuántas variables, para esto usamos cualquiera de los dos siguientes códigos/comandos:
des, short
describe
Este es el resultado al usar des, short. Tenemos 35 673 personas, 3 variables y luego información acerca del tamaño del dataset.

Este es el resultado usando describe:

Ahora la pregunta es: ¿Cómo puedo ver el número de missing values en mi dataset/base de datos? en otras palabras ¿Está completa la información de las tres variables o hay missing values? Voy a usar el comando mdesc para averiguar esto, veamos el resultado:
Este es el resultado :

¿Qué significa este resultado? Significa que las variables Residence Area y Age tienen 3 858 missing values, es decir 3 858 personas de este dataset no tienen información en las variables Residence Area y Age.
¿Qué implicaciones tienen los missing values para nuestro análisis? Una gran cantidad de missing values puede afectar la validez (the validity) de nuestro estudio, en otras palabras puede llevarnos a conclusiones erróneas. En este momento cabe preguntarse: ¿son esas 3 858 personas con missing values diferentes a los que no tienen missing values? ¿Esas 3 858 personas eran del área rural o eran mayoritariamente del área urbana? ¿Eran más jovenes que los que tienen información completa o eran mayores? Cuando las obsevaciones que tienen missing values son diferentes a los que no la validez de nuestros resultados podría verse comprometida debido a sesgo de selección.
Conclusión:
- No basta saber únicamente el número de observaciones en nuestro dataset, sino si hay también missing values y cuáles son las variables con missing values.
- mdesc es una entre varias alternativas que Stata ofrece para describir la distribución de missing values.
- Debe encontrarse la manera de identificar si las observaciones con missing values son diferentes a la muestra de estudio.
- SPSS no ofrece una opción directa que al igual que mdesc nos de la distribución de missing values.