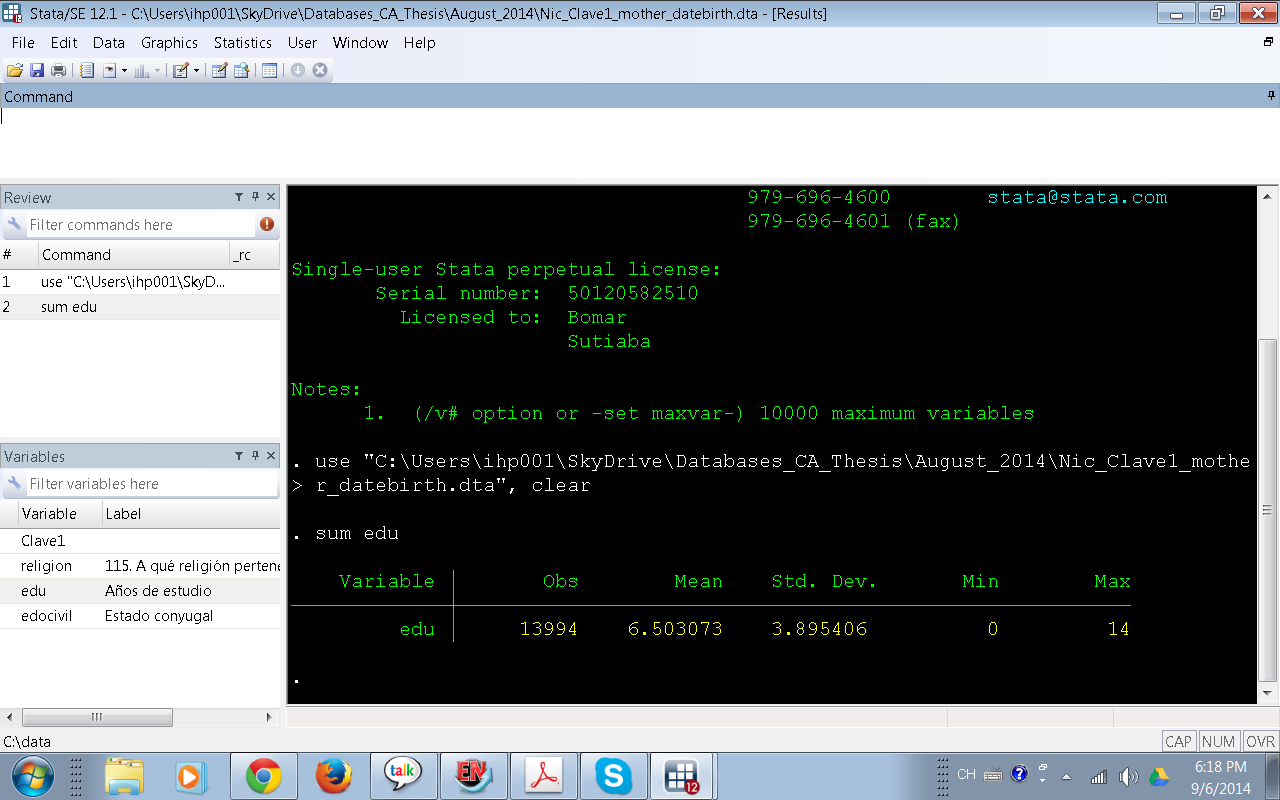
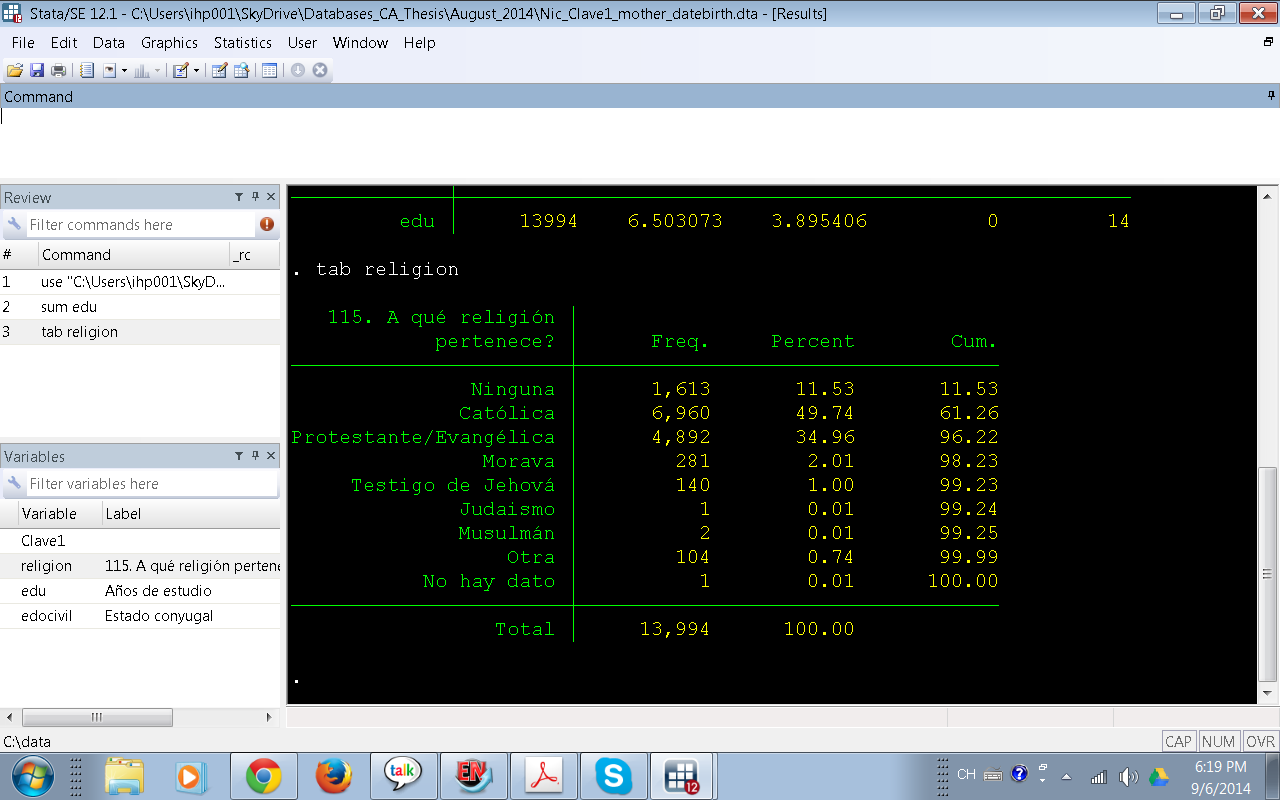
Frecuentemente tenemos variables continuas (o numéricas por ejemplo edad) en nuestro dataset y es posible que necesitemos convertir esta variable de numérica a una categórica. Antes de mostrar cómo hacer este proceso llamado recodificación me detendré un momento para pensar por qué necesitaríamos transformar una variable númerica a una categórica? Respuestas a esta preguntan incluyen:
- Comparabilidad con investigaciones previas. Nuestros resultados serán comparados con otros estudios y si los otros estudios han usado la variable edad como categórica en vez de continua también nosotros debemos recodificarla.
- Comparar un grupo etario con otro, por ejemplo por alguna razón relacionada a nuestra investigación podríamos estar interesados en comparar las personas de 30 o más años con los de 25 años o menos y en este caso también tendríamos que recodificar la variable numérica.
Ahora voy a mostrar cómo hacer la recodificación de variables en Stata (en próximo post mostraré cómo hacerlo en SPSS). Para este fin voy a utilizar una base de datos de ejemplo disponible por Stata corp, para acceder a esta base simplemente abrimos Stata:
Luego copiamos y pegamos esta dirección: use http://www.stata-press.com/data/r12/census2.dta y damos enter.
Una vez demos enter veremos las variables (en mi caso las variables se muestran en la esquina inferior izquierda) pero por defecto Stata muestra las variables en la esquina superior derecha.
Si bien para motivos de este post estoy usando este dataset de ejemplo, usar dataset de ejemplo acarrea el problema de que no estamos familiarizados con el dataset, no conocemos qué variables tiene? cómo están etiquetadas? qué tipo de variables son, si son numéricas o categóricas?
Para simplificar el proceso de recodificación de la variable continua a categórica voy a usar la variable age en la base de datos de ejemplo. Primero voy a mostrar como podemos verificar qué tipo de variable vamos a usar (es continua o categórica?). Hay varias maneras de hacer esto, pero en este post voy a mostrar dos que son comunes y muy útiles:
- Usando el comando codebook
- Usando el comando list
Los comandos codebook y list nos ayudan a saber si en este dataset la variable age es continua o no. La manera de usar estos comandos es escribiendo el comando seguido por el nombre de la variable:
codebook age
list age
Usemos el comando codebook primero:
Después de dar enter obtenemos el siguiente resultado:
¿Qué significa este resultado? Tenemos información del tipo de variable y dice que es numeric o sea continua; vemos que los valores de esta variable van de 24 a 35 y que no hay missing values en 50 observaciones (0/50) (también puedes revisar el post de noviembre de 2014 acerca de missing values) . Ojo aún no hemos iniciado la recodificación de la variable, sólo estamos verificando qué tipo de variable es age en este dataset. Si bien podríamos detenernos aqui mismo e iniciar el proceso de recodificación a continuación por motivos de usar el comando list voy a continuar "verificando" qué variable es age.
Voy a escribir list age in 1/10 ¿Por qué tengo que escribir list nombredevariable in número/número? La razón que escribo in 1/10 es para especificar que quiero ver los valores de la variable age en las primeras 10 filas de la base de datos. Si quisiera por ejemplo ver los valores de age en las filas digamos 11 al 20 tendría que escribir:
list age in 11/20
y obtenemos el siguiente resultado:
¿Cómo este resultado nos ayuda a ver qué tipo de variable es age? Al ver los valores de la variable en las primera 10 filas vemos que son números 29, luego 26, 29 otra vez, etc por lo que estoy sumado al resultado de codebook nos ayuda a ver que age es una variable continua. En la última imagen de este post vuelvo a usar el comando list para comparar una variable continua y una categórica, comparación que ayuda a habituarnos a distinguir entre estos dos tipos de variables.
Desde aqui inician los pasos para recodificar age (o cualquier otra variable continua) a categórica:
Paso 1: Este primer paso no tiene que ver con el software en si, tiene que ver con cómo queremos recodificar nuestra variable. Asumamos que estamos interesados en comparar el grupo etario menor de 25 años con 26 a más años.
Paso 2: Conozcamos el mínimo y el máximo de nuestra variable. Para esto escribimos el siguiente comando:
Veamos el resultado:
Paso 3: Escribamos el comando para recodificar la variable y generar una nueva variable (que se llamará edad) al mismo tiempo:
recode age (24/25=1 "Menor o igual a 25") (26/35=0 "Mayor o igual a 26"), gen(edad)
Paso 4: Corroboremos si la variable fue creada de acuerdo a lo que esperabamos, para esto usamos el comando tab con la nueva variable recien creada.
tab edad
Veamos el resultado:
Vemos que ahora tenemos una variable categórica en vez de una continua. Para finalizar voy a mostrar los valores de la variable original (age) y la variable nueva (edad).
list age edad in 1/10
Veamos los resultados:
En conclusión:
- Los comandos codebook y list nos ayudan a explorar rápidamente nuestra base de datos. Funcionan tanto para variables numéricas como categóricas.
- En Stata una variable numérica puede ser transformada a categórica siguiendo 4 pasos (una vez que estamos seguros que la variable original es continua).
- Es recomendable usar el comando tab después de finalizar la recodificación.