
¿Por dónde empezar? Nuestro análisis no puede estar desvinculado de nuestra hipótesis u objetivos de investigación los cuales deben estar escritos en nuestra propuesta (protocolo) de investigación . Los siguientes pasos constituyen una guía para iniciar el análisis cuantitativo de nuestros datos, aunque los pasos son válidos para cualquier software en este post me enfocaré en Stata.
1.-¿Cuál es nuestra variable dependiente (también llamada variable resultado o Y)? Es conveniente identificar en nuestra base de datos cuál es el nombre de nuestra variable dependiente. ¿Existe en la base de datos? o debemos construirla? En caso de que ya exista debemos modificar el número categorías? Supongamos que nuestra variable dependiente es Nivel educativo de mujeres en Edad Fértil y que nosotros estamos interesados en Educación Primaria y Educación Secundaria. ¿Dónde está esta variable en nuestra base de datos? En la penúltima columna de la base de datos está la variable edu (Nivel Educativo de las Mujeres en Edad Fértil) ¿Qué tipo de variable es TotgradoMEF? Basados en la inspección del Editor de datos (primera figura) sospechamos que esta variable es continua, comprobemos nuestra presunción calculando el promedio (aunque basta con calcular el promedio para saber si es númerica o no también Stata nos da la desviación estándard , el mínimo y el máximo)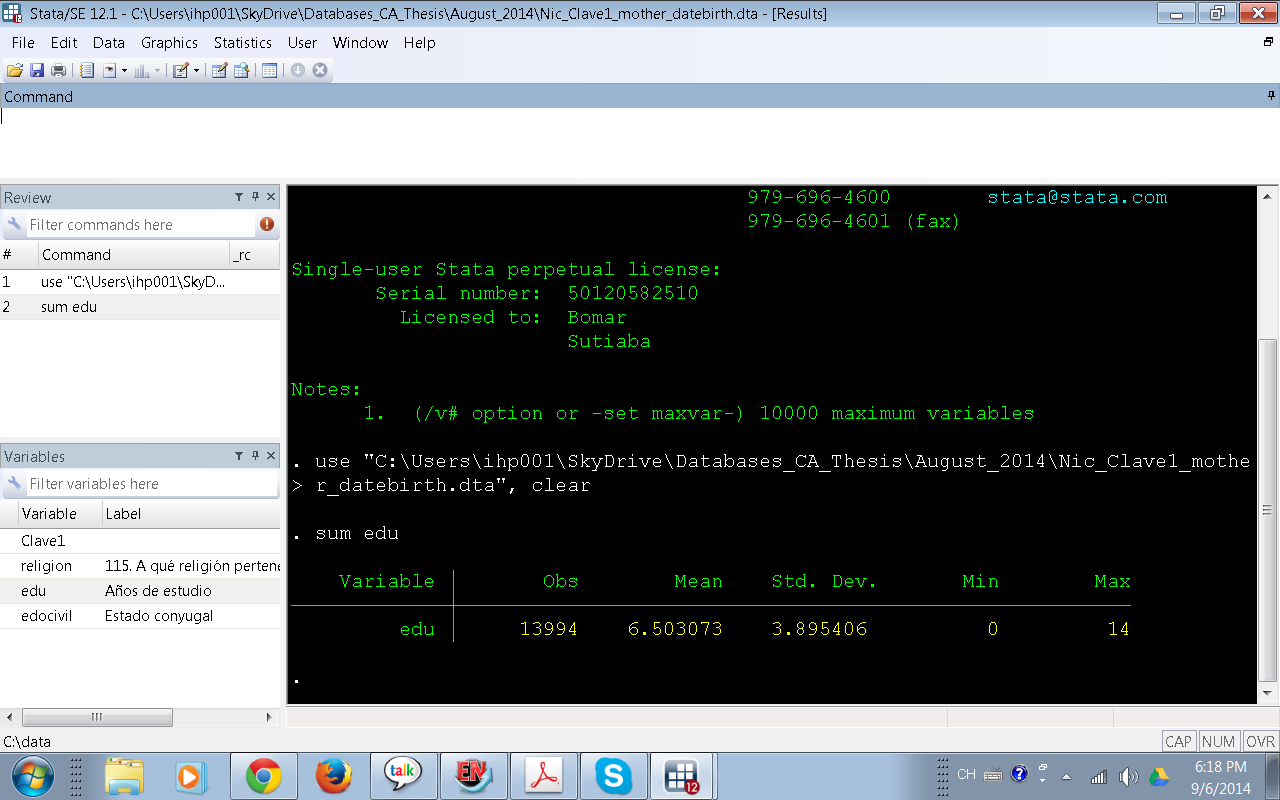
Vemos que es una variable continua (numérica) que contiene información del total de años de estudio por cada Mujer en Edad Fértil. El mínimo es cero años y el máximo 21 años, el promedio de años de estudio es 7.2 años y la desviación estándard es 4.56 ¿Qué debemos hacer a continuación? Debido a que nuestro interés es tener una variable dependiente dicotómica (de dos categorías: Educación Primaria y Educación Secundaria) claramente debemos recodificar la variable continua para transformala a categórica. Está más allá de los objetivos de este post mostrar como se recodifica una variable.
2.-¿Cuál(es) es(son) nuestra(s) variables independientes (también llamada variable predictora/explicativa o X)? Igualmente a como identificamos la variable dependiente debemos identificar la o las variables independientes . Supongamos que en nuestra investigación las variables independientes son: religion y Edocivil (Estado civil). ¿Existen en la base de datos? Claramente en el editor de datos vemos (primera imagen) que existen. ¿Qué tipo de variable es y cuántas categorías tiene? Para responder estas preguntas debemos hacer una frecuencia de cada una de estas variables, veamos para Religión:
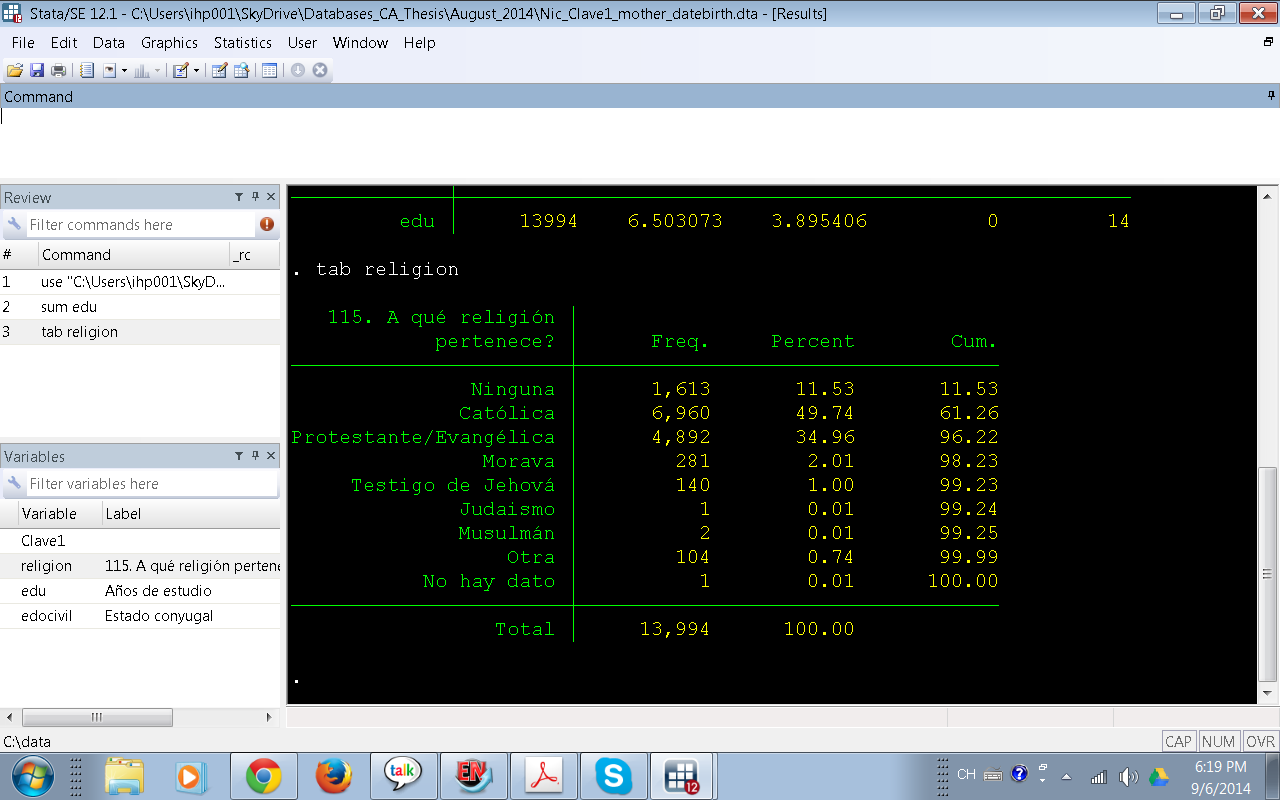
Ahora veamos la frecuencia simple para Estado Civil

¿Entonces qué tipo de variables son religion y edocivil? Son variables categóricas. Dependiendo de nuestro interés es posible que necesitemos o no recodificar estas variables debido a que algunas categorías tienen relativamente pocos casos en comparación con otras, por ejemplo hay 61 observaciones en la categoría "Divorciada", esta categoría se podría fusionar con "Separada", "Viuda" y "Soltera" para crear una nueva categoría llamada "Sin Pareja", pero va más allá de los objetivos de este post mostrar cómo se recodifica una variable.
En conclusión:
- Identifiquemos las variables dependiente e independientes.
- Realicemos frecuencia simple (para variables categóricas) o promedio (para variables numéricas) para evaluar si es necesario modificar las variables (por ejemplo transformar una variable continua a categórica o recodificar las variables),
No hay comentarios:
Publicar un comentario